|
Listen to this article
 |
At Agility Robotics, we are working with our humanoid robot Digit, which balances actively at all times, can recover from unexpected bumps, and can lift and move heavy things. There are 28 degrees of freedom and quite a few sensors. That’s a lot of information to take in, and a lot of actuators to coordinate, for complex actions that need to be decided in real time.
Every action or contact with the environment, like grasping a doorknob, can be felt at every joint of the robot and affects how the legs should balance the entire thing.
So let’s start by talking about the two major approaches to controlling a dynamic robot like this:
- Using a model-based controller
- Using a learned controller
In many cases. the company uses model-based control and inverse dynamics to solve this problem. The model is a simplified physics model of Digit, running online on the computer inside the robot, calculating things like where to place a foot to balance the robot, based on measurements from the onboard inertial measurement unit and all of the position sensors.
We then use inverse dynamics, which uses a model of the humanoid’s link masses, inertias, actuators, and so on, to calculate the torques we need at each joint to get to the action we want from the model-based controller (i.e., how to get the foot to a certain place). This set of calculations must happen reliably in real time, hundreds or thousands of times per second.
But building up this kind of model and making the computation efficient can be quite challenging, since it requires us to enumerate all the details of physics that might be relevant, from the possible friction models of the terrain, to the possible types of errors in our joint sensors. It’s incredibly powerful, but it requires us to know a lot about the world.
Reinforcement learning (RL) is a totally different way of solving the same problem. Instead of using the robot and world models onboard in real-time to calculate the motor torques that we think will lead to the physics we want, we simulate worlds to learn a control policy for the robot ahead of time, on off-board computers that are much more powerful than the on-board robot computers.
We model the simulated robot in as much detail as possible, in a simulated world that has the expected obstacles and bumps, and try millions of possible sets of motor torque commands, and observe all of the possible responses. We use cost functions to judge whether a command achieves a more or less useful response
Over the course of significant simulation time — but only hours in real time — we learn a control policy that will achieve the goals we want, like walk around without falling, even if there’s an unexpected pothole in the ground. This means that we don’t need to exactly know what will happen in the real world; we just need to have found a controller that works well across a bunch of different worlds that are similar enough to the real one.
It trades off modeling effort for computational effort. And it means that we can learn controllers that explore the limits of what might be physically possible with the robot, even if we don’t know exactly what those boundaries are ourselves.

Training Digit in simulation through NVIDIA’s tools designed for robotics. | Source: NVIDIA
We’ve been able to demonstrate this in areas like step-recovery, where physics are particularly hard to model. In situations where Digit loses its footing, it’s often a result of an environment where we don’t have a good model of what’s going on – there might be something pushing on or caught on Digit, or its feet might be slipping on the ground in an unexpected way. Digit might not even be able to tell which issue it’s having.
But we can train a controller to be robust to many of these disturbances with reinforcement learning, training it on many possible ways that the robot might fall until it comes up with a controller that works well in many situations. In the following chart, you can see how big of a difference that training can make:
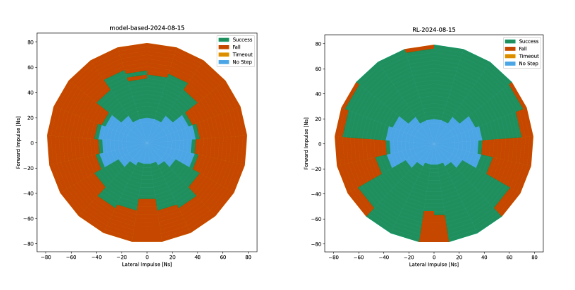
Comparing performance of model-based controller (left) against a controller trained with reinforcement-learning (right). | Source: Agility Robotics
Early last year, we started using NVIDIA Isaac Lab to train these types of models. Working with NVIDIA, we were able to make some basic policies that allowed Digit to walk around. But, to be honest, they started out with some weird behaviors.
One thing that we did get immediately, however, was the ability to run a lot more of our experiments. Moving to Isaac Lab and a GPU-accelerated environment was much faster than running simulations on the CPU. This enabled us to iterate much more quickly and start to identify the key area that we needed to improve:
Figuring out Agility Robotics’ Sim2Real gaps
In reinforcement learning, perhaps the biggest challenge is figuring out how to make a policy trained in a simulator transfer over to a real robot (hence the term “Sim2Real”). There are a lot of small differences between the real world and a simulated one, and even if you simulate a lot of worlds with a lot of variations, you might be missing some important component that always happens in the real world and never happens the same way in your simulations.
In our case, toe impacts are one such area. With every footstep, Digit impacts the ground with one of its toe plates. And the result of that impact is hard to predict.
Impacting the ground is already a very chaotic physical problem. (“Chaotic” in the formal sense, which is that very small deviations in the input can lead to unbounded variations in the output over time.)
Depending on exactly how your foot lands, you might slip, or have a lot of grip. You might be able to exert a lot of force, or only a little. And that small variation can lead to a big change in the outcome when you predict where the rest of your torso will end up.
This is exactly what happened with some of our earlier Isaac Lab policies. In simulation, the robot would walk confidently and robustly. But in the real world, it would slip and slide around wildly.
When you encounter a Sim2Real gap like this, there are two options. The easy option is to introduce a new reward, telling the robot not to do whatever bad thing it is doing. But the problem is that these rewards are a bit like duct tape on the robot — inelegant, missing the root causes. They pile up, and they cloud the original objective of the policy with many other terms. It leads to a policy that might work, but is not understandable, and behaves unpredictably when composed with new rewards.
The other, harder, option is to take a step back and figure out what it is about the simulations that differ from reality. Agility as a company has always been focused on understanding the physical intuition behind what we do. It’s how we designed our robot, all the way from the actuators to the software.
Our RL approach is no different. We want to understand the why and use that to drive the how. So we began a six-month journey to figure out why our simulated toes don’t do the same thing as our real toes.
It turns out there are a lot of reasons. There were simplifying assumption in the collision geometry, inaccuracies in how energy propagated through our actuators and transmissions, and instabilities in how constraints are solved in our unique closed-chain kinematics (formed by the connecting rods attached to our toe plates and tarsus). And we’ve been systematically studying, fixing, and eliminating these gaps.
The net result has been a huge step forward in our RL software stack. Instead of a pile of stacked-reward functions over everything from “Stop wiggling your foot” to “Stand up straighter,” we have a handful of rewards around things like energy consumption and symmetry that are not only simpler, but also follow our basic intuitions about how Digit should move.
Investing the time to understand why the simulation differed has taught us a lot more about why we want Digit to move a certain way in the first place. And most importantly, coupled with fast NVIDIA Isaac Sim, a reference application built on NVIDIA Omniverse for simulating an testing AI-driven robots, it’s enabled us to explore the impact of different physical characteristics that we might want in future generations of Digit.

An example of a revised toe/foot concept (left), using four contact points, instead of the traditional shoe-style tread (right). | Source: Agility Robotics
We’ll be talking more about these topics at the 2024 Conference on Robot Learning (CoRL) next week in Munich, Germany. But the moral of the story is that understanding the dynamics of the world and our robot, and understanding the reasons for sources of noise and uncertainty rather than treating the symptoms, have let us use NVIDIA Isaac Lab to create simulations that are getting closer and closer to reality.
This enables simulated robot behaviors to transfer directly to the robot. And this helps us create simple, intuitive policies for controlling Digit that are more intelligent, more agile, and more robust in the real world.
Editor’s note: This article was syndicated, with permission, from Agility Robotics’ blog.
 About the author
About the author

Pras Velagapudi is the chief technology officer at Agility Robotics. His specialties include industrial automation, robotic manipulation, multi-robot systems, mobile robots, human-robot interaction, distributed planning, and optimization. Prior to working at Agility, Velagapudi was the vice president and chief architect of mobile robotics at Berkshire Grey.




Tell Us What You Think!